I have very recently completed the Stanford Lagunita online course on Statistical Learning, and Tibrishani & Hastie have taught me a great deal about Principal Components. No learning is complete without exercises, however, so I have found a wonderful data set that seems popular, the attacks and weaknesses of Pokemon. (I am, admittedly, not a pokemon player, so I have had to ask others to help me understand some of the intricacies of the game.)
Principal Component Decomposition:
First and foremost, principal component decomposition finds the direction that maximizes variation in the data. At the same time, this can be said to be the eigenvalue of the data, the direction which best describes the direction of the data.
For example, if there is a spill of dirt on a white tile floor, the direction of the spill (eigenvalue) would always be the direction the dirt is most widely spread (principal component).
After looking at the beautiful charts used in the link above, I realized this would be very interesting to do a PCD on. What Pokemon are most similar and which are most different in terms of strengths and weaknesses? To find out we will break it into its principal components, and find out in which directions the data is spread out.
Pokemon can vary along 18 dimensions of strengths and weaknesses, since there are 18 types of Pokemon. This means there can be up to 18 principal components. We are not sure which principal components are useful without investigation. We show below how much variation is explained by each type of Pokemon. There doesn’t appear to be any clear point where there the principal components drop off in their usefulness, perhaps the first 3 or the first 5 seem to capture the most variation. The amount of variation captured by each principal component is outlined below.

Let us now look at the principal components of the Pokemon attack/weakness chart directly. We can visualize them in a biplot, where the arrows show the general attacking direction of the pokemon and the black labels show the defending labels. The distance from the center of biplot shows the deviation of that pokemon type from the central eigenvalue/principal component. Labels that are close together are more similar than those further apart.

So for example, Ghost attacks (arrows) are closely aligned with Ghost defence (black label) and Dark defence (black label). In general, the Pokemon that are most different in defence is Fighting and Ghost, and still again distinct from Flying and Ground defence. This suggests that if you wanted a Pokemon portfolio that would be very resilient to attack, you would want Fighting/Ghost types. If you want a variety of attacks, you might want to look into Ghost/Normal types or Grass/Electric.
Keep in mind together these only explain about 35.5% of the variation of Pokemon types, there are other dimensions in which Pokemon vary. I expected fire and water to be more clearly different (and they are very distinct, they go opposite directions for a long distance from the center!), but they are less distinct than ghost/normal.
The Optimum Pokemon Portfolio:
This lead me to wonder what type of pokemon portfolio would be best against the world, something outside the scope of the Statistical Learning course but well within my reach as an economist. Since I don’t know what the pokemon-world looks like, I assumed the pokemon that show up are of a randomly and evenly selected type. (This is a relatively strong assumption, it is likely the pokemon encounters are not evenly distributed among the types). The question is then, what type of pokemon should we collect to be the best against a random encounter, assuming we simply reach into our bag and grab the first pokemon we see to fight with?
First, I converted the matrix of strengths and weaknesses above into one that describes the spread of the strength-weakness gap, that is to say, if Water attacks Fire at 200% effectiveness, and defends at 50% effectiveness, a fight between the Water and Fire is +150% more effective than a regular pokemon attack (say Normal to Normal or Ice to Ice). Any bonuses a pokemon may have against its own type was discarded, because it would be pointless. The chart for this, much like the wonderful link that got me the data in the first place, is here, where red is bad and blue is good: 
Then I added the strength-weakness gap together for each type of pokemon, which assumes that the pokemon are facing an a opponent of a random type. According to this then, the most effective type of pokemon are on average:
Type Effectiveness Steel 0.22222222 Fire 0.11111111 Ground 0.11111111 Fairy 0.11111111 Water 0.08333333 Ghost 0.08333333 Flying 0.05555556 Electric 0.00000000 Fighting 0.00000000 Poison -0.02777778 Rock -0.02777778 Dark -0.02777778 Ice -0.08333333 Dragon -0.08333333 Normal -0.11111111 Psychic -0.11111111 Bug -0.11111111 Grass -0.19444444
That is to say, Steel pokemon, against a random opponent, will on average be 22% more effective. (This is the mean, not the median.) And against a random opponent a Grass pokemon will be expected to be 19% less effective than a Fighting pokemon, shockingly low. Amusingly, Normal pokemon are worse than normal (0) against the average pokemon.
This does not mean you ONLY want Steel pokemon because you could come up with an opponent that is strong against Steel. Nor do you want to entirely avoid Grass pokemon, since they are very strong against many things that Steel is weak against. Merely that if you’re willing to roll the dice, a Steel pokemon will probably be your best bet. Trainers do not want to take strong risks, trainers are risk averse. You want to maximize your poke-payoff while minimizing how frequently you face negatively stacked fights. The equation for this is:

Where 
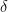
How risk averse are you? You could be very risk averse and want to never come across a bad pokemon to fight, or you could love rolling the dice and only want one type of pokemon. So I have plotted the optimal portfolio for many levels of risk-tolerance. It is a little cluttered, so I have labelled them directly as well as in the legend.

The visualization is indeed a little messy, but as you become more risk averse, you add more Electric, Normal, Fire, and Ice pokemon (and more!) to help reduce the chance of a bad engagement. In order to do this, one reduces the weight we put on Steel, Ground, and Fairy pokemon, but doesn’t eliminate them entirely. Almost nothing adds Dragon, Ghost, Rock. or Bug pokemon, they are nearly completely dominated by other combinations of pokemon types.
I’ve plotted two interesting portfolios along the spectrum of risk aversion below. They include one with nearly no risk aversion (0.001), and one with high risk aversion (10).
Of course, most importantly of all, regardless of your Pokemon and your interest in being “the very best”, you should still pick the coolest Pokemon and play for fun.
Code is included below:
#Data from: https://github.com/zonination/pokemon-chart/blob/master/chart.csv
#write.csv(chart, file="/home/bsweber/Documents/poke_chart.csv")
poke_chart<-read.csv(file="/home/bsweber/Documents/poke_chart.csv")
poke_chart<-poke_chart[,-1]
library(quadprog)
# library(devtools)
# install_github("vqv/ggbiplot", force=TRUE)
library(ggbiplot)
library(reshape2)
library(ggplot2)
library(ggrepel)
poke_chart<-as.matrix(poke_chart)
differences <- (poke_chart-1) - (t(poke_chart)-1)
diag(differences)<-0
rownames(differences)<-colnames(differences)
core <- poke_chart
rownames(core)<-colnames(poke_chart)
poke_pcd<-prcomp(core, center=TRUE, scale=TRUE)
plot(poke_pcd, type="l", main="Pokemon PCD")
summary(poke_pcd)
biplot(poke_pcd)
poke_palette<-c("#A8A878", "#EE8130", "#6390F0", "#F7D02C", "#7AC74C", "#96D9D6", "#C22E28", "#A33EA1", "#E2BF65", "#A98FF3", "#F95587", "#A6B91A", "#B6A136", "#735797", "#6F35FC", "#705746", "#B7B7CE", "#D685AD")
ggbiplot(poke_pcd, labels= rownames(core), ellipse = TRUE, circle = TRUE, obs.scale = 1, var.scale = 1) +
scale_color_discrete(name = '') +
theme(legend.direction = 'horizontal', legend.position = 'top')
#Score plot is for rows, attack data. loading lot is for columns, defense data. So bug and fairy have similar attacks (shown by rays), similar defences (shown by points). Ghost and normal have almost identical defences, but different attacks.
ggbiplot(poke_pcd, labels= colnames(core), ellipse = TRUE, circle = TRUE, obs.scale = 1, var.scale = 1, choice=c(2,3)) +
scale_color_discrete(name = '') +
theme(legend.direction = 'horizontal', legend.position = 'top') #Score plot is for rows, attack data. loading lot is for columns, defense data.
ggbiplot(poke_pcd, labels= colnames(core), ellipse = TRUE, circle = TRUE, obs.scale = 1, var.scale = 1, choice=c(5,6)) +
scale_color_discrete(name = '') +
theme(legend.direction = 'horizontal', legend.position = 'top') #Score plot is for rows, attack data. loading lot is for columns, defense data.
ggbiplot(poke_pcd, labels= colnames(core), ellipse = TRUE, circle = TRUE, obs.scale = 1, var.scale = 1, choice=c(7,8)) +
scale_color_discrete(name = '') +
theme(legend.direction = 'horizontal', legend.position = 'top') #Score plot is for rows, attack data. loading lot is for columns, defense data.
cov_core<- t(differences-mean(differences)) %*% (differences-mean(differences)) #Make the Cov. Matrix of differences.
cov_core[order(diag(cov_core), decreasing=TRUE),order(diag(cov_core), decreasing=TRUE)]
ones<-as.matrix(rep(1,18))
vars<-as.matrix(rep(1/18, times=18))
mu<-t(as.matrix(apply(differences/18, 1, sum))) #Average rate of return over 18 pokemon types.
data.frame(mu[,order(t(mu), decreasing=TRUE)]) #Table of Pokemon Types
colnames(mu)<-colnames(core)
delta<- 1 #risk aversion parameter
out<- matrix(0, nrow=0, ncol=18)
colnames(out)<-colnames(core)
for(j in 1:1000){
delta<-j/100
Dmat <- cov_core * 2 * delta
dvec <- mu
Amat <- cbind(1, diag(18))
bvec <- c(1, rep(0, 18) )
qp <- solve.QP(Dmat, dvec, Amat, bvec, meq=1)
pos_answers<-qp$solution
names(pos_answers)<-colnames(poke_chart)
out<-rbind(out, round(pos_answers, digits=3))
}
df <- data.frame(x=1:nrow(out))
df.melted <- melt(out)
colnames(df.melted)<-c("Risk_Aversion", "Pokemon_Type", "Amount_Used")
df.melted$Risk_Aversion<-df.melted$Risk_Aversion/100
qplot(Risk_Aversion, Amount_Used, data=df.melted, color=Pokemon_Type, geom="path", main="Pokemon % By Risk Aversion") +
# ylim(0, 0.175) +
scale_color_manual(values = poke_palette) +
# geom_smooth(se=FALSE) +
geom_text_repel(data=df.melted[df.melted$Risk_Aversion==8.5,], aes(label=Pokemon_Type, size=9, fontface = 'bold'), nudge_y = 0.005, show.legend = FALSE)
# Another plot that is less appealing
# matplot(out, type = "l", lty = 1, lwd = 2, col=poke_palatte)
# legend( 'center' , legend = colnames(core), cex=0.8, pch=19, col=poke_palatte)
pie(head(out, 1), labels= colnames(out), col=poke_palette)
pie(tail(out, 1), labels= colnames(out), col=poke_palette)
df_1<-data.frame(matrix(out[1,], ncol=1))
colnames(df_1)<-c("Percentage")
df_1$Pokemon_Type<-colnames(out)
ggplot(data=df_1, aes(x=Pokemon_Type, y=Percentage, fill=Pokemon_Type))+
geom_bar(stat="identity", position=position_dodge()) +
scale_fill_manual(values = poke_palette)+
ggtitle("Pokemon Portfolio With Almost No Risk Aversion")
df_2<-data.frame(t(tail(out,1)))
colnames(df_2)<-c("Percentage")
df_2$Pokemon_Type<-colnames(out)
ggplot(data=df_2, aes(x=Pokemon_Type, y=Percentage, fill=Pokemon_Type))+
geom_bar(stat="identity", position=position_dodge()) +
scale_fill_manual(values = poke_palette) +
ggtitle("Pokemon Portfolio With Very Strong Risk Aversion")
cov_core[order(diag(cov_core), decreasing=TRUE),order(diag(cov_core), decreasing=TRUE)]
melt_diff<-melt(t(differences))
melt_diff$value<- factor(melt_diff$value)
N<-nlevels(melt_diff$value)
simplepalette<-colorRampPalette(c("red", "grey", "darkgreen"))
ggplot(data = melt_diff, aes(x=Var1, y=Var2, fill=value) ) +
geom_tile()+
scale_fill_manual(values=simplepalette(9), breaks=levels(melt_diff$value)[seq(1, N, by=1)], name="Net Advantage" )+
ggtitle("Net Pokemon Combat Advantage")+
xlab("Opponent") +
ylab("Pokemon of Choice")

Leave a comment